
Benötigte Lesezeit: 5 Minuten
Deep Learning (tiefgehendes Lernen, Anm. d. Red.) ist ein Teilbereich des maschinellen Lernens, bei dem Algorithmen das Lösen von Aufgaben durch Rohdaten erlernen.
Maschinelles Lernen und Deep Learning ermöglichen das Lösen einer Aufgabe mit Hilfe von Algorithmen und Rechenkraft. Beide Methoden werden beim maschinellen Sehen oder der Verarbeitung von Sprache angewendet. Eine typische Herausforderung ist die Einordnung von Bildern: Wie kann eine Maschine erkennen, ob ein Foto eine Katze oder einen Hund zeigt?
Maschinelles Lernen versus Deep Learning
Beim maschinellen Lernen werden Algorithmen verwendet, um Daten zu analysieren, aus diesen Daten zu lernen und fundierte Entscheidungen auf der Grundlage des Gelernten zu treffen. Anstatt Softwareroutinen zur Ausführung einer Aufgabe von Hand zu codieren, werden Algorithmen mithilfe von definierten und strukturierten Datensätzen „trainiert“. Bleiben wir bei dem Beispiel der Bilderkennung: Beim maschinellen Lernen werden die Bilder vorab „gelabelt“. Das heißt, der Mensch gibt vor, welches Bild einen Hund und welches eine Katze zeigt. Dieser Datensatz wird dann zum Trainieren verwendet.
Deep Learning strukturiert Algorithmen in Schichten, und erschafft so ein „künstliches neuronales Netzwerk“, das selbst lernt. Künstliche neuronale Netze, die Deep Learning verwenden, senden die Eingabe (Informationen der Bilder) durch verschiedene Schichten des Netzwerks und definieren spezifische Merkmale. Im Fall von Katzen und Hunden sind das zum Beispiel die Form des Gesichts, Ohren, Fell, Nase, Schnurrhaare oder Augen. Nachdem die Daten verarbeitet wurden, identifiziert das System selbst die geeigneten Charakteristiken, um etwa Hunde oder Katzen zu klassifizieren.
Warum ist Deep Learning aktuell so beliebt?
Warum kommen Deep Learning Modelle aktuell so häufig zum Einsatz? Dafür gibt es vier Gründe:
- Größere Datenmengen: Durch die Nutzung des Internets stehen größere Datenmengen zur Verfügung. Damit können komplexe Modelle trainiert und schwierigere Aufgaben gelöst werden.
- Mehr Rechenleistung: Durch die Evolution von z.B. GPUs (Grafikprozessor) können Deep Learning Architekturen heute rechnerisch immer besser gemanagt werden.
- Große Modelle sind tatsächlich leichter zu trainieren. Zwar existierten ähnliche Architekturen bereits vor einem Jahrzehnt. Sie waren jedoch wesentlich kleiner und unflexibel und daher schwerer zu trainieren.
- Flexibilität: Heutige Modelle können leicht zusammengesetzt werden, um relevante Berechnungen durchzuführen. Sie sind wie sehr flexible, rechnergestützte Lego-Teile, die angepasst werden können.
Neuronale Netze – das Gehirn der künstlichen Intelligenz
Künstliche neuronale Netze (im Englischen Artificial Neural Networks = ANN) wurden vom menschlichen Gehirn und den biologischen Prozessen der Informationsverarbeitung inspiriert. Biologische neuronale Netze bestehen aus Zellen, die Neuronen genannt werden. Sie sind durch Dendriten miteinander verbunden. Verbindungen, Synapsen genannt, senden ein Signal, welches sich durch den Dendriten in den Zellkörper ausbreitet. Sobald ein bestimmter Schwellenwert im Zellkörper erreicht wird, sendet das Neuron eine Spitze entlang des Axons, welches mit ungefähr 100 weiteren Neuronen verbunden ist. Diese stark verbundenen parallelen Signale verbreiten sich dann.
Künstliche neuronale Netze sind ebenfalls eine Sammlung von Einheiten (Neuron oder Perzeptron genannt) die miteinander verbunden sind und Signale austauschen, ganz wie echte Nervenzellen.
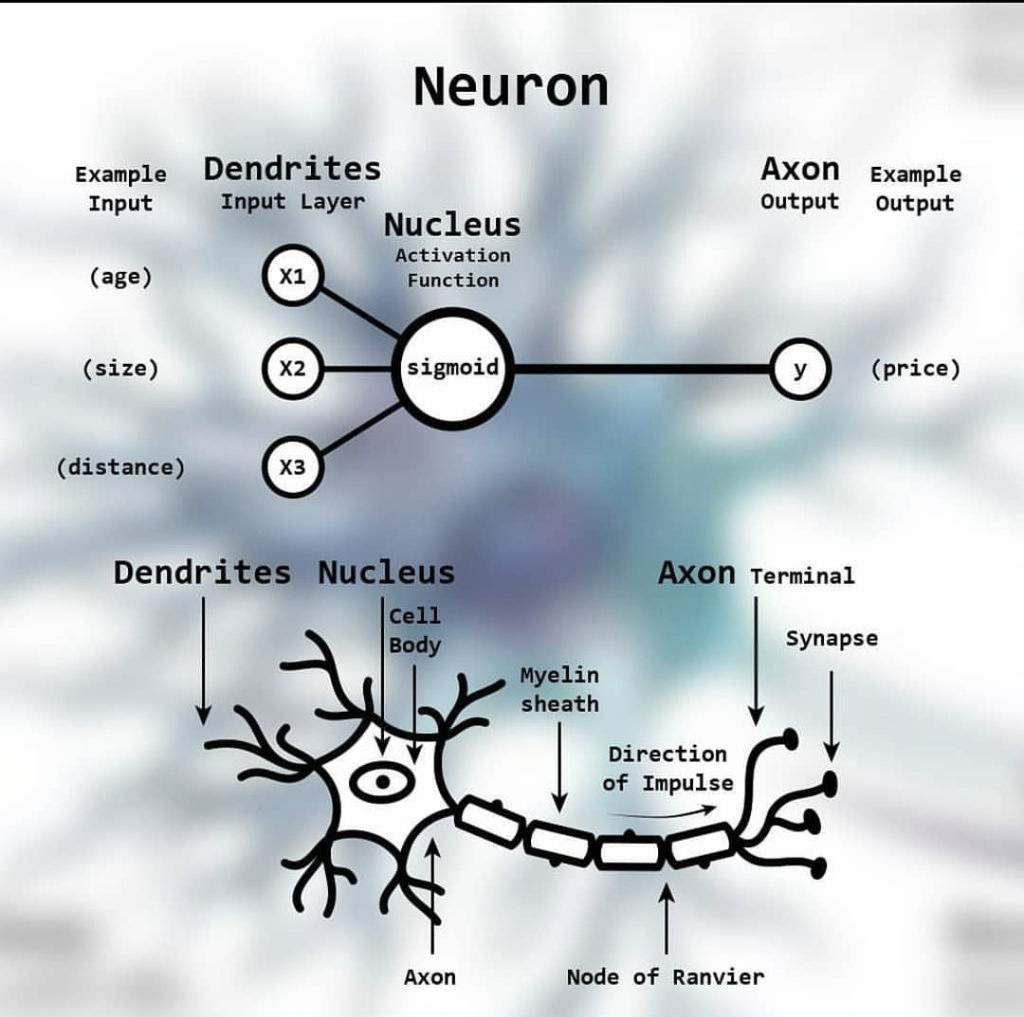
Diese „Signale“ bestehen aus purer Mathematik. Wen die Kalkulationen im Detail interessieren, dem empfehle ich den einstündigen, englischsprachigen Kurs „Einführung ins Deep Learning“ vom Massachusetts Institute of Technology. Das Grundprinzip läuft folgender Maßen ab: Es werden Eingaben (etwa eine Information oder Daten, im Englischen „Input“ genannt) für ein Neuron definiert, die unterschiedlich gewichtet sind. Daraus wird eine Summe gebildet, welche im Anschluss eine (nicht-lineare) Aktivierungs-Funktion durchläuft. Ein Beispiel dafür ist die sogenannte Sigmoid-Funktion. Das ergibt dann eine Ausgabe (im Englischen „Output“ genannt). Dieses Resultat dient dann als Input für das nächste Neuron. Auf diese Weise können mehrere Perzeptrone zu komplexen hierarchischen Darstellungen zusammengesetzt werden. Solche Netzwerke werden dann mathematisch optimiert und anschließend trainiert.
Die Verarbeitung hunderter oder tausender Parameter erhöht die Komplexität und macht es schwierig, die Vorgänge im Netz zu visualisieren oder vollständig zu verstehen. Diese fehlende Transparenz erschwert die Fehlerbeseitigung (Debugging). Forscher beschäftigen sich aus diesem Grund verstärkt mit dem Kreieren effektiver Netzwerkarchitekturen und Algorithmen und dem besseren Verstehen ihrer mathematischen Bestandteile.
Wie genau funktioniert Deep Learning? Ein Beispiel.
Vereinfachtes Beispiel für die Funktionsweise eines neuronalen Netzwerkes aus dem Kurs „Einführung ins Deep Learning“ vom Massachusetts Institute of Technology:
Eine Studentin belegt einen Kurs und möchte herausfinden, ob sie diesen bestehen wird oder nicht (binäre Klassifizierung). Ein einfaches Modell wird dazu mit zwei Eingaben (Input) gefüttert: a) Die Anzahl der besuchten Vorlesungen und b) die Anzahl der Stunden, die sie für ihre Projekte aufwendet.
Die historische Datengrundlage zum Trainieren des Modells, besteht aus dem Verhalten (a und b) und Resultaten (bestanden/nicht bestanden) vorheriger Teilnehmer.
Das Modell kalkuliert zunächst basierend auf alten Daten, etwa mit den Werten a und b des Studenten X, einen Output.
- Diese erste Berechnung ergibt, dass Student X den Kurs mit einer bestimmten Wahrscheinlichkeit bestanden hat.
- Doch das Ergebnis ist noch nicht korrekt. Denn das Modell muss erst „lernen“, was als Versagen und was als Erfolg bezeichnet wird. Dazu wird es trainiert: Das Training erfolgt, indem das tatsächliche Resultat für Student X mit dem kalkulierten Resultat verglichen wird. Daraus ergibt sich eine Fehlerrate.
- Das Ziel ist nun, diese Rate für den gesamten Datensatz zu minimieren. Hierzu werden Berechnungen ausgeführt, die sich langsam an den idealen Wert herantasten. Dadurch entsteht eine Trainingsschleife. Das Modell berechnet im Grunde fortlaufend Vorhersagen, die dann bewertet werden und angeben, wie falsch das Netzwerk bei dieser Iteration lag.
- Dieser Optimierungsvorgang wird solange wiederholt, bis der Wert den tatsächlichen Resultaten aus dem historischen Datensatz ausreichend ähnelt.
- Anschließend kann die Studentin ihre eigenen Eingaben (a und b) verwenden und eine sehr wahrscheinliche Einschätzung erhalten, ob sie den Kurs erfolgreich abschließen wird.
Mein Fazit: Deep Learning ist ein sehr komplexes Thema. Es erfordert einen signifikanten Abstecher in die Mathematik und oft mehrere Anläufe, um ein grundlegendes Verständnis zu entwickeln. Da Deep Learning jedoch den Kern der aktuellen technischen Entwicklungen darstellt, kommt man um die Materie nicht herum.
Quellen:
- Handbuch der Künstlichen Intelligenz, 5. Auflage, Günther Görz, Josef Schneeberger, Ute Schmidt
- Artificial Intelligence – A Modern Approach, 3rd Edition, Stuart Russell, Peter Norvig
- https://de.wikipedia.org/wiki/Deep_Learning
- https://de.wikipedia.org/wiki/Hebbsche_Lernregel
- www.youtube.com/watch?v=-SgkLEuhfbg
- https://hackernoon.com/deep-learning-vs-machine-learning-a-simple-explanation-47405b3eef08
Titelbild: DALLE 2

